

今回の日経225先物miniの自動売買での一番重要な処理がAWSの「Lambda」です。
Lambdaはサーバー不要でCloud上で動作するプログラムになります。常時稼働しておきたい自動売買の場合はLambdaでは実現困難ですっが、日経225先物miniを日中セッション、夜間セッションと時間指定で自動売買したい場合にはLambdaで実現可能です。
AWSのアカウントの登録方法などは割愛しておりますので、下記参考ページなどでAWSアカウントの準備をお願いします。

 ロボトレ
ロボトレLambdaが自動売買運用のメインの処理を行う一番の大事な部分にあたるよ。それでは始めてみよう!
Lambdaで実装する機能概要
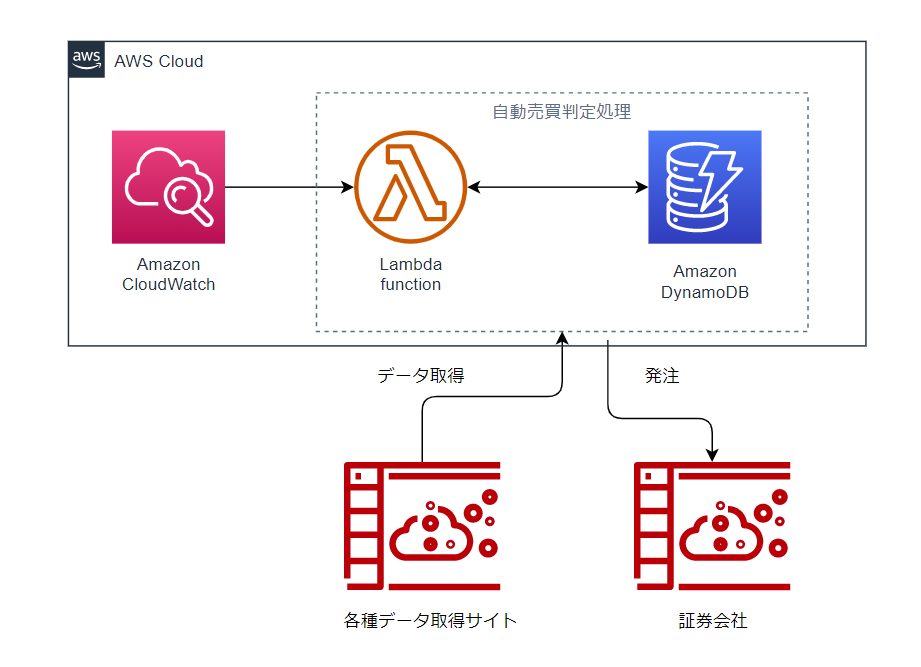
今回は自動売買の運用で一番大事なLambda処理部分を作成していきます。
LambdaはいろいろなAWSのサービスから呼ばれて処理を行うところになります。日経225先物miniの発注を①日中セッション開始前、②夜間セッション開始前と1日2度の注文をAWSの「CloudWatch」というサービスを用いて「Lambda」の処理を開始させ自動売買処理を行います。
AWS「CloudWatch」から呼び出された際に、日中セッションの発注か夜間セッションの発注かを判定します。
Lambda上でSeleniumを用いて225Laboサイトから日経225miniの価格データExcelファイルをダウンロードします。
今回用いる手法は前セッションの高値安値のブレイクアウト手法を用いています。
シンプルな手法ではありますが、トレンド発生時などには強力です。逆にレンジ相場の場合は損が続くので中が必要です。

2015年1月~2021年9月までのバックテスト結果
今回ご紹介する手法はあくまでもご自身の判断でご利用ください。
損をしてもロボトレでは責任を負いませんのでご了承ください。
SBI証券の先物取引画面上で注文が存在する場合は、一括キャンセルを行います。
CloudWatchを利用すると極稀に2回動作してしまうことがあり、重複発注を回避するために、必ず今ある注文を削除致します。
手動での注文がSBI証券上に存在すると、正常に自動売買が行えないため、
手動で売買を行う場合には、他の証券会社で行うなどの工夫が必要です。
セッション開始前に建玉がある場合には、成行決済注文を行います。
こうすることで、次回セッション開始時に決済&発注が同時に行われることになります。
SBI証券にログインから始まり、先物取引画面に遷移後、注文を行います。
SBI証券では「OCO注文」が可能なため、こちらの注文を利用して前回高値に買い逆指値、前回安値に売り逆指値の注文を実施します。
Tips
Lambdaはサーバーレスで起動するため、あまりにも時間がかかる処理には不適合です。
だいたい私の運用では3分以内に発注まで終わる処理をLambdaで運用しています。
ロボトレお待たせしました。
ここからは実際にLambdaの設定となります!
Lambda関数の設定方法
Lambda関数作成
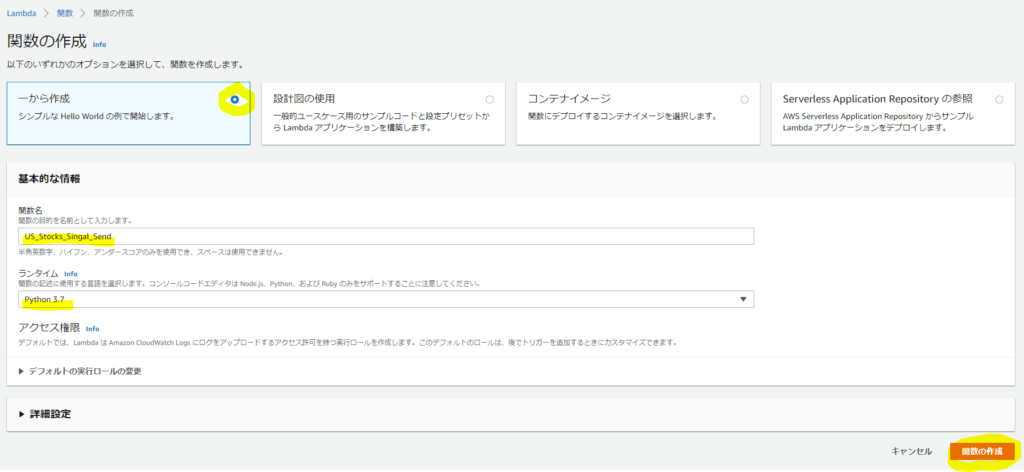
AWSにログイン後、Lambdaのページで「関数の作成」を押下

一から作成を選択し、関数名を適当に入力、ランタイムに「Python3.7」を選択し、関数の作成ボタンをクリック
※Pythonは3.8の場合後記するパッケージ名などが異なってきますので、注意してください。
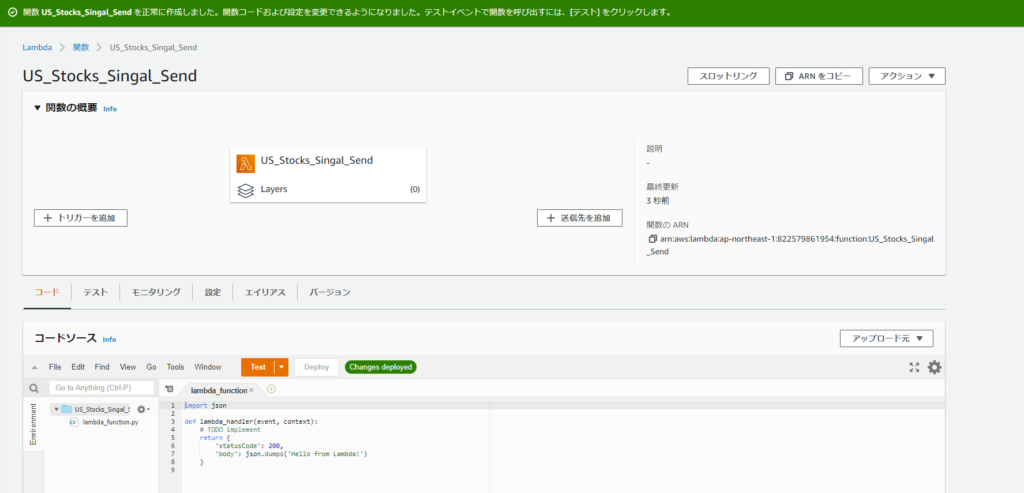
数秒経つとLambdaの関数が作成されます。
レイヤーの設定
Lambdaは標準的な関数を利用することができません。そこで、レイヤーという設定項目で利用したい関数群を指定し設定することでLambda関数内で利用することが出来るようになります。
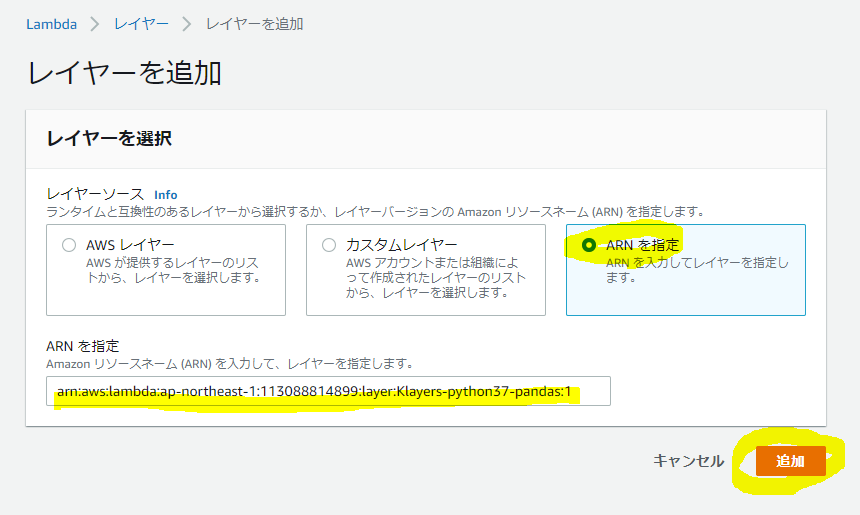
Lambda関数画面の下の方にあるレイヤー枠でレイヤーの追加ボタンをクリック

ARNを指定を選択し、ARNを指定し、追加ボタンをクリックします。尚、下記のレイヤーを追加いたします。
- arn:aws:lambda:ap-northeast-1:113088814899:layer:Klayers-python37-pandas:1
※PythonでDataFrameを利用するためのPandas関数 - arn:aws:lambda:ap-northeast-1:113088814899:layer:Klayers-python37-openpyxl:6
※PythonでExcelファイルを読み込むのに必要な関数 - arn:aws:lambda:ap-northeast-1:822579861954:layer:headlessChrome:2
※WEB画面を操作するSelenium関数(自作)
自作のSelenium関数のレイヤーについてはこちらのファイルを利用してますので、ダウンロードしご利用ください。
ダウンロードしたファイルのレイヤー登録方法はこちらを参考にしてください。

レイヤー3つを登録すると下記のイメージの通りにレイヤーが3つと表示されます。
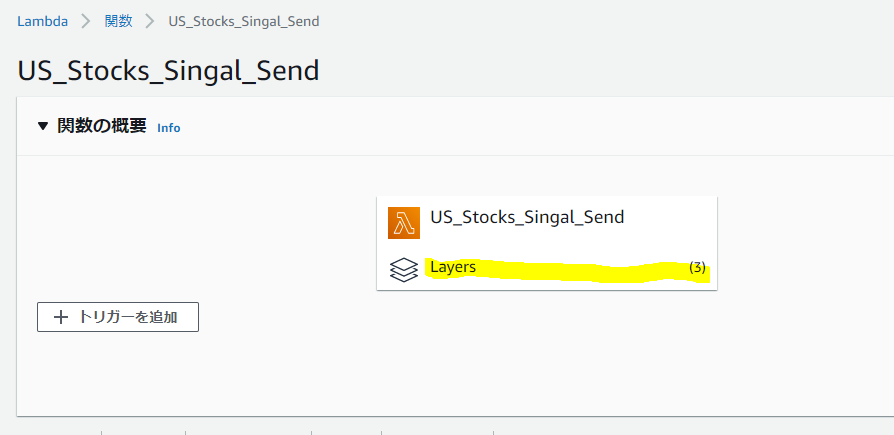
Lambdaの設定
Lambda作成初期の設定のままですと何かと不便なため、設定を変更していきます。
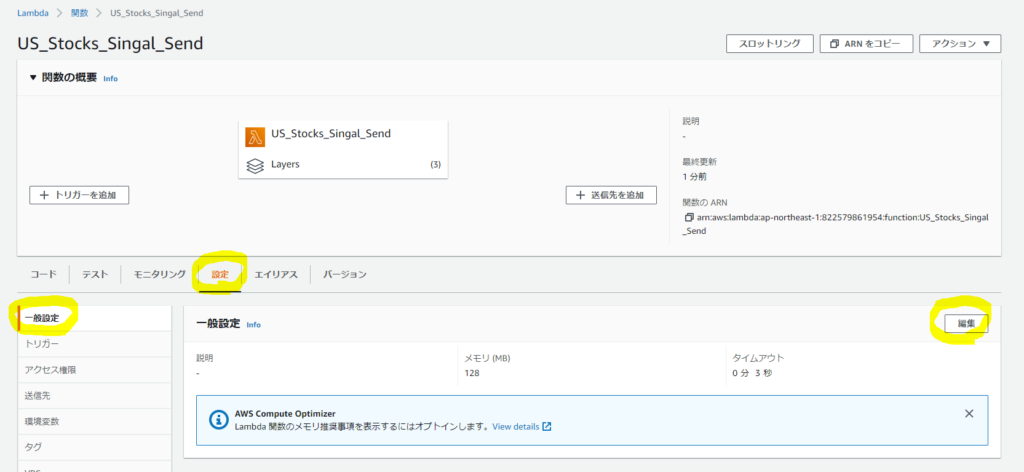
設定タブを選択し、一般設定を選択、編集ボタンをクリックします。
メモリを1600MB、タイムアウトを2分以上で設定致しました。このあたりはご自身の処理したい内容から変更して頂ければ結構です。
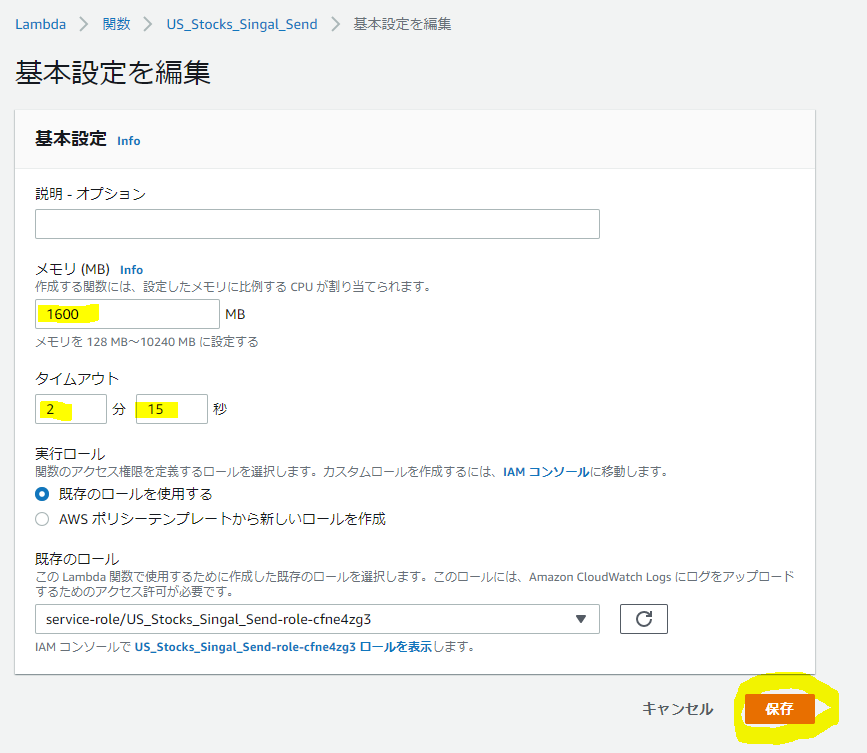
これでLambdaの設定は完了です。
Lambda関数処理
ここからは関数の作成(Pythonによるプログラミング)となりますが、重要な箇所をピックアップして記載いたします。
Chromeブラウザの起動とダウンロードフォルダ指定
from datetime import datetime, timedelta
from dateutil.parser import parse
from time import sleep
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support.select import Select
driver_path = '/opt/bin/chromedriver'
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument("--disable-gpu")
options.add_argument('--window-size=1280,800')
options.add_argument("--disable-application-cache")
options.add_argument("--disable-infobars")
options.add_argument("--no-sandbox")
options.add_argument("--hide-scrollbars")
options.add_argument("--enable-logging")
options.add_argument("--log-level=0")
options.add_argument("--v=99")
options.add_argument("--single-process")
options.add_argument("--ignore-certificate-errors")
options.add_argument("--homedir=/tmp")
options.binary_location = "/opt/bin/headless-chromium"
# ブラウザを起動する
driver = webdriver.Chrome(
driver_path, chrome_options=options)
driver.set_window_size(1920,1080)
driver.maximize_window()
# ヘッドレスChromeでファイルダウンロードするにはここが必要だった
driver.command_executor._commands["send_command"] = ("POST", '/session/$sessionId/chromium/send_command')
driver.execute("send_command", {
'cmd': 'Page.setDownloadBehavior',
'params': {
'behavior': 'allow',
'downloadPath': '/tmp' # ダウンロード先
}
})重要なのはLambda上で動作するヘッドレスChromeの場合、明示的にダウンロード先を指定する必要があります。
このように設定することで下記の様にファイルを取得利用することが出来るようになります。
import pandas as pd
dictDF = pd.read_excel('/tmp/N225minif_2021.xlsx', index_col=0, engine='openpyxl', sheet_name=['日中日足', 'ナイト場足','取引日日足'])ローソク足(価格)データ取得
ChromeブラウザをSeleniumを利用し、必要なローソク足データをダウンロードあるいはWEBから取得します。
各証券会社や会員制情報サイトや取引所サイトなどから私は取得しています。
今回は一例として225Laboから取得行います。
VERSION = '1.0'
from datetime import datetime, timedelta
from dateutil.parser import parse
from time import sleep
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support.select import Select
import os
import webbrowser
import time
import json
import zipfile
import logging
LABO225_URL = {
'login' : 'https://225labo.com/user.php',
'download' : 'https://225labo.com/modules/downloads_data/index.php?cid=3'
}
class LABO225_Utility:
logger = logging.getLogger(__name__)
def __init__(self,
userId,
pw,
driver_path,
*_, **__):
self.userId = userId
self.pw = pw
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument("--disable-gpu")
options.add_argument('--window-size=1280,800')
options.add_argument("--disable-application-cache")
options.add_argument("--disable-infobars")
options.add_argument("--no-sandbox")
options.add_argument("--hide-scrollbars")
options.add_argument("--enable-logging")
options.add_argument("--log-level=0")
options.add_argument("--v=99")
options.add_argument("--single-process")
options.add_argument("--ignore-certificate-errors")
options.add_argument("--homedir=/tmp")
options.binary_location = "/opt/bin/headless-chromium"
# ブラウザを起動する
driver = webdriver.Chrome(
driver_path, chrome_options=options)
driver.set_window_size(1920,1080)
driver.maximize_window()
# ヘッドレスChromeでファイルダウンロードするにはここが必要だった
driver.command_executor._commands["send_command"] = ("POST", '/session/$sessionId/chromium/send_command')
driver.execute("send_command", {
'cmd': 'Page.setDownloadBehavior',
'params': {
'behavior': 'allow',
'downloadPath': '/tmp' # ダウンロード先
}
})
self.logger.info(
'''
225LABO開始
[{}]
'''.format(datetime.now().strftime('%Y%m%d %H:%M:%S')))
self.driver = driver
self.logger.debug(self.__dict__)
def login(self):
self.logger.info('225LABOへログイン開始')
self.driver.get(LABO225_URL['login'])
WebDriverWait(self.driver, 30).until(expected_conditions.visibility_of_element_located((By.NAME, "uname")))
self.driver.find_element_by_name("uname").clear()
self.driver.find_element_by_name("uname").send_keys(self.userId)
self.driver.find_element_by_name("pass").clear()
self.driver.find_element_by_name("pass").send_keys(self.pw)
self.driver.find_element_by_xpath("//*[@id='ModuleContents']/form/div/table/tbody/tr[3]/th/input").click()
# ログイン成功判定
WebDriverWait(self.driver, 30).until(expected_conditions.visibility_of_element_located((By.ID, "acc_btn")))
self.logger.info('225LABOへログイン完了')
#
# ダウンロードへ遷移
#
def downloadData(self):
# ダウンロードファイル削除
if os.path.exists('/tmp/N225minif_2021.zip'):
self.logger.info('N225minif_2021.zipファイル削除')
os.remove('/tmp/N225minif_2021.zip')
self.logger.info('ダウンロード開始')
self.driver.get(LABO225_URL['download'])
WebDriverWait(self.driver, 30).until(expected_conditions.visibility_of_element_located((By.ID, "down_pro_list")))
self.driver.find_element_by_xpath('//*[@id="down_pro_list"]/tbody/tr[1]/td[2]/p[2]/a').click()
self.logger.info('ダウンロード完了')
time.sleep(10)
self.logger.info('ダウンロードファイル解凍開始')
# ダウンロードファイル解凍
with zipfile.ZipFile('/tmp/N225minif_2021.zip') as existing_zip:
existing_zip.extractall('/tmp')
self.logger.info('ダウンロードファイル解凍完了')
'''
225LABOデータ取得終了
'''
def exit(self):
self.logger.info('Chromeを閉じる 開始')
self.driver.quit()
self.logger.info('Chromeを閉じる 完了')
'''
225LABOデータ取得処理
'''
def start_download(self):
try:
self.logger.debug('ダウンロード処理')
# ログイン
self.login()
# ダウンロード処理
self.downloadData()
self.exit()
except Exception as e:
print(str(e))
self.logger.error(str(e))
self.driver.save_screenshot("screen.png")
self.exit()証券会社に発注
日本国内の証券会社であれば比較的容易にSeleniumで実装が可能です。
今回はSBI証券での自動発注を行いますが、かなり長くなりますのでGitHubにソースを上げておきますのでそちらをご確認ください。
基本的に証券会社では自動発注は好ましくなく不正と扱われる可能性がありますので、重々承知の上で自己判断でご使用ください。
Lambdaの設定完了時のイメージ
最終的なLambdaに必要な各種pythonのファイルやConfigファイルは下記を参考にしてください。

各種ファイルをLambda上に配置することで下記の画像のようになり完成となります。
※getNikkeiData.pyは不要です。
まとめ
Lambda上での「Seleniumを用いた自動化」や「Excelファイルのダウンロード」は結構つまづくPointでしたので、要点を説明しました。ソース内は初心者なので汚いですがお許しください。。
今後はご自身の戦略(ストラテジー)に内容を変更することで、ぐっと自動売買の幅が広がります。
ロボトレはこれをベースにいくつもの自動売買を運用を行っています。
ロボトレデータの取得方法や戦略は多種多様なので、ご自身の手法に合わせてカスタマイズをしてくださいね。

